Loss function 개념
loss function,objective function,cost function(손실함수)는 지도 학습시 알고리즘이 예측한 값과 실제 정답의 차이를 비교하기 위한 함수즉 학습 중에 알고리즘이 얼마나 잘못 예측하는 정도를 확인하기 위한 함수로서 최적화(optimization)를 위해 최소화 하는 것이 그 목적인 함수 .
손실함수를 통해 모델 학습 중에 손실이 커질 수록 학습이 잘 안되고 있다고 해석할 수 있고, 반대로 손실이 작아질 수록
학습이 잘 이루어지고 있다고 해석합니다.
손실 함수는 성능 척도와는 다른 개념으로, 성능 척도는 학습된 알고리즘의 성능을 정량적으로 평가하기 위한 지표로서
accuracy,f1스코어 등이 있음
즉, 성능 지표는 알고리즘의 학습이 끝났을 때 모델의 성능을 평가하기 위한 지표이기에 알고리즘 학습 중에는 전혀 사용 되지 않음.
반면,손실 함수는 알고리즘 학습 중에 학습이 얼마나 잘 되고 있는지를평가하기 위한 지표
결국 예측값(Y^)이 정답(Y)와 최대한 근접하게 만드는 과정으로 x,y는 고정 된값이므로 ,알고리즘 학습시 사용되는 최적의
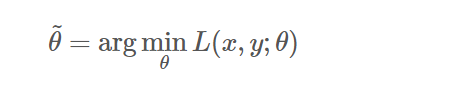
파라미터 세타를 찾아 loss를 최소화 하는 과정
활성화 함수의 개념
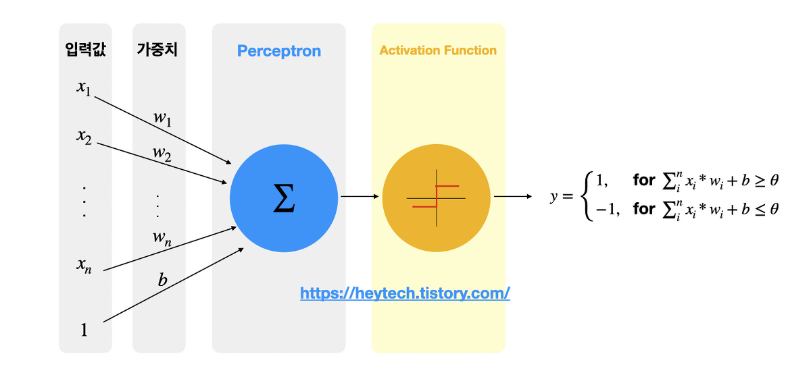
활성 함수란 퍼셉트론의 출력값을 결정하는 비선형 함수로 즉 입력값의 총합을 출력할지 말지 결정하고, 출력한다면
어떤 값으로 변환하여 출력할지 결정하는 함수입니다.
활성함수 종류
1. sign 함수
위의 퍼셉트론에서는 signㅎ마수를 활성화 함수로서 활용, Sign 함수의 활성화 함수는 퍼셉트론 내 입력값의 총합이 0보다 작을 경우 −1을 출력하고, 반대로 0보다 클 경우 1을 출력하는 역할을 합니다
2. sigmoid 함수
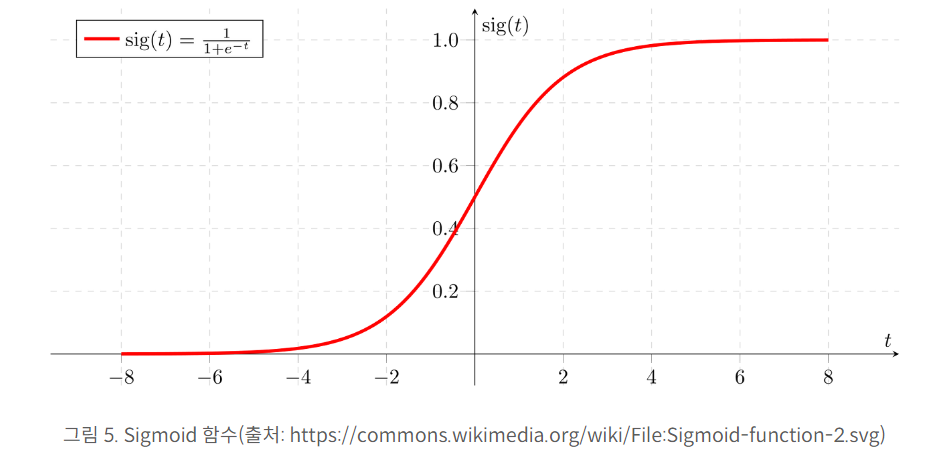
(1)모든 입력값에 대해 출력값을 실수값으로 정의 (=soft decision)
(2) 값이 작아질수록 0 ,커질 수록 1에 수렴
(3) 출력이 0~1 사이로 확률 표현 가능(=binary classification)
3. softmax 함수
softmax 함수는 N가지 출력값을 갖는 함수로 입력값을 N가지 클래스 중 하나로 분류하는 multi-class classification에 주로 사용
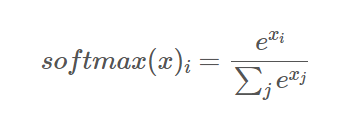
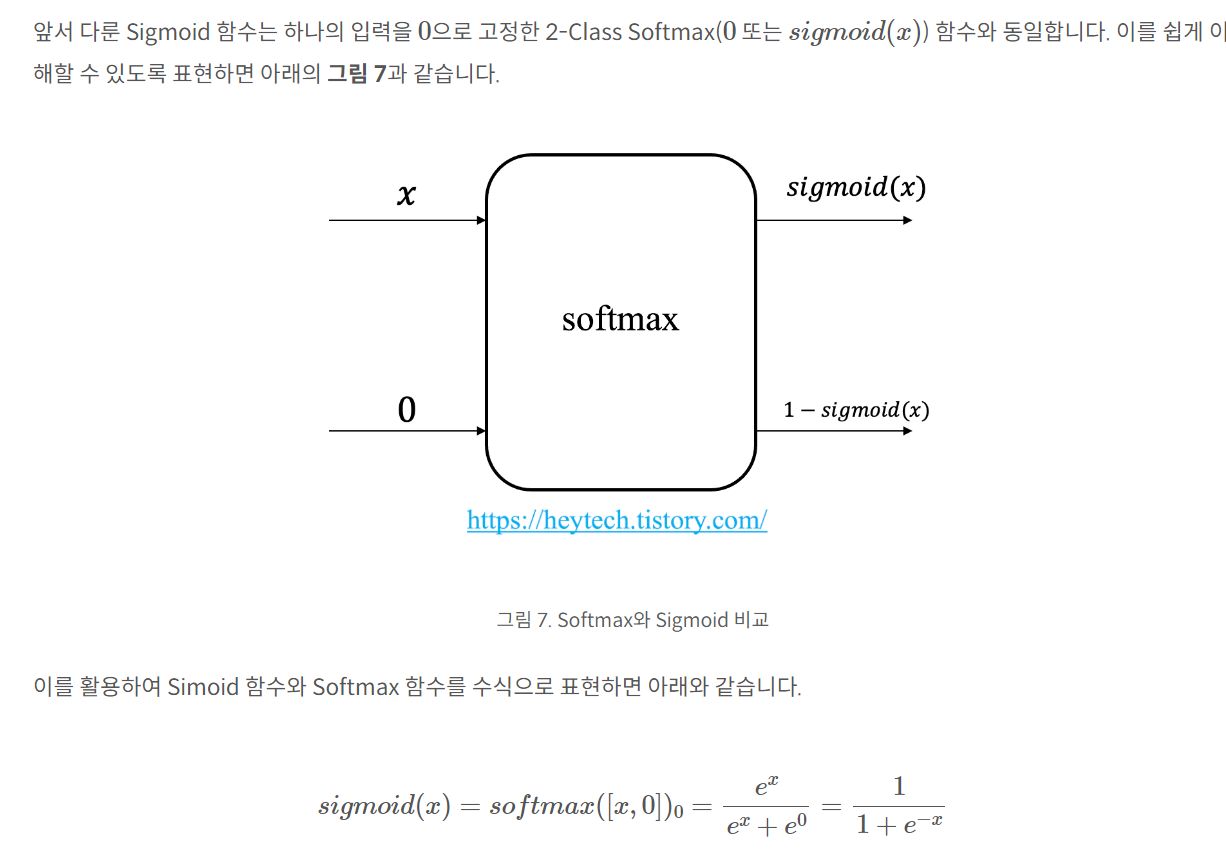
특징 :
(1)출력값이 N개
(2) 입력값을 지수함수로 취하고 이를 정규화 (총합을 1로 만듦)
(3) 정규화로 인해 각 출력값은 0~1 값을 가짐
(4) 모든 출력값의 합은 반드시 1
(5) N가지 중 한가지에 속할 확률 표현 가능(multi -class classification)
결론 :
모든 출력값의 합은 1이므로 sigmoid 함수의 다른 출력값은 (1-sigmoid(x)) 와 같이 표현할 수
MSE : 모델의 예측 값과 실제 값 차이의 제곱의 평균
-> 예측값과 실제값간 평균오차가 가장 적은 선형 함수를 찾도록 모델링
4. ReLU 함수
렐루는 y=x인 선형함수가 입력값 0이하에서부터 rectified된 함수
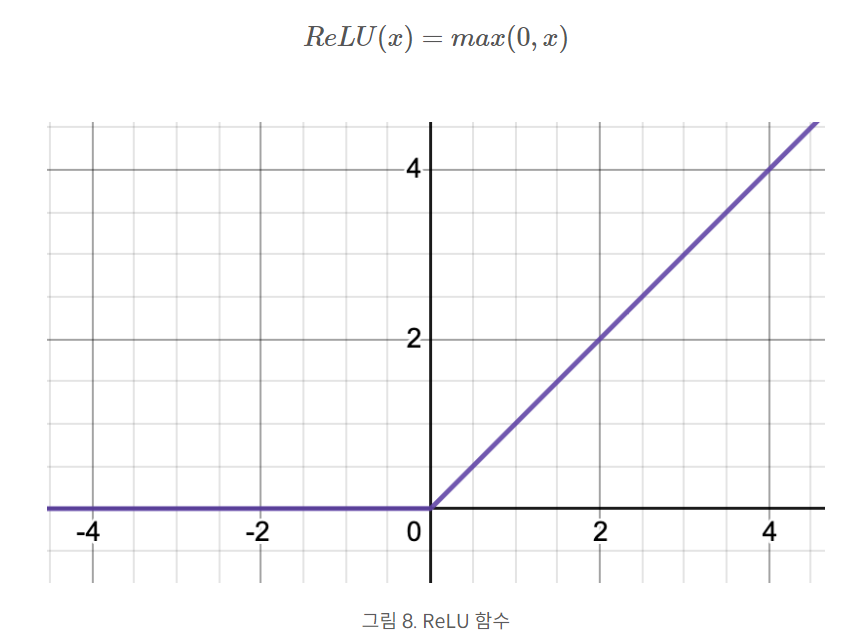
특징 :
(1) 딥러닝 분야에서 가장 많이 사용되는 활성화 함수
(2) sigmoid,tanh 함수의 vanishing gradient 문제 해결
(3) 입력값이 음수일 경우 출력값과 미분값을 모두 0으로 강제하므로 죽은 뉴런을 회생하는 데 어려움 존재
(4) 구현이 단순하고 연산이 필요 없이 임계값(양수/음수 여부)만 활용하므로 연산속도가 빠름
5. Leaky Relu 함수
ReLU 함수에서 발생하는 Dying ReLU 현상을 보완하기 위해 다양한 변형된 ReLU 함수가 제안되었습니다. 그중에서 Leaky ReLU에 대해 알아봅니다. Leaky ReLU는 입력값이 음수일 때 출력값을 0이 아닌 0.001과 같은 매우 작은 값을 출력하도록 설정합니다. 수식은 다음과 같습니다.
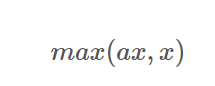
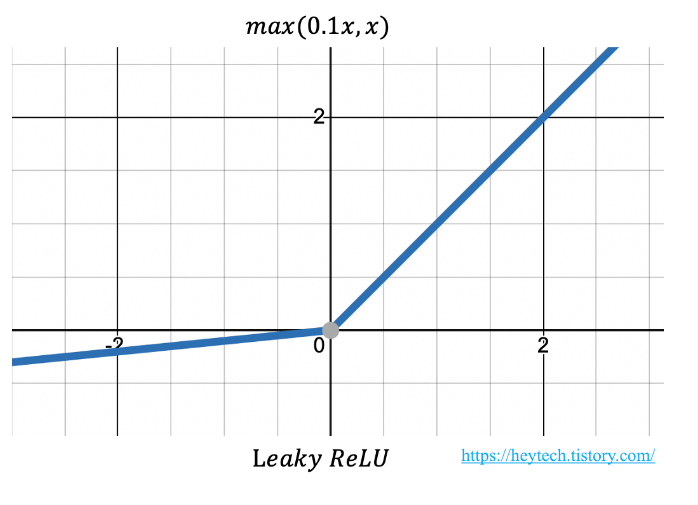
여기서 �는 0.01,0.001과 같이 작은 값 중 하나로 하이퍼파라미터입니다(그림 9 참고). Leaky는 사전적으로 '(물이나 연기 등이)새어 나가는' 같은 의미가 있습니다. 여기서 말하는 '새어 나가는' 정도를 입력값이 음수인 경우의 기울기를 나타냅니다. 이처럼 �는 0이 아닌 값이기 때문에 입력값이 음수라도 기울기가 0이 되지 않아 뉴런이 죽는 현상을 방지할 수 있습니다
logit : odds에 자연로그를 취한 함수를 logit이라고 하는데 어떤 사건이 벌어질 확률 p가 [0,1]사이의 값일 때
이를 -무한대 ~ + 무한대 사이 실수값으로 변환하는 과정을 logit 변환이라고 함결국 로짓 변환을 통해 확률 값을 무한대 실수값으로 변환할 수 있게 되면서 , 드디어 확률을 예측하는 회귀 모델식을 가정확률에 대해 정리하여 나온 최종 식을 로지스틱 함수라고 하며, 독립변수 X가 주어졌을 때 종속 변수가 특정 class에 속할 확률을 의미
sigmoid : 딥러닝에서 로지스틱을 함수를 시그모이드라고 부르기도 함, 시그모이드 함수는 신경망의 가중치가 바뀌는 과정에 연속성을 부여, 초기 신경망 모델은 계단 함수와 같은 비연속적인 활성 함수를 사용했고 학습의 효율성이 낮았는데, 결국 인간의 연속적인 학습과정을 모방하기 위해 시그모이드 함수와 같은 연속적인 함수가 활성화 함수로 사용 됨
상태가 2개인 경우에 한해서 인공신경망 마지막 LAYER에 확률 값을 변환하는 역할로 활용될 수 있음, 시그 모이드 함수의 정의 자체가 logit함수의 역변환
logit 변환의 의미 : score
로짓은 확률값으로 변환되기 직전의 최종 결과 값,다른 말로는 Score
분류 계열의 신경망 모델의 마지막 layer 에서는 소프트맥스 함수가 활용되는데, 로짓함수는 소프트 맥스 함수에 그 값을 전달해주는 역할을 합니다.
소프트 맥스: 로지스틱 함수의 다차원 일반화 개념, 종속 변수의 상태가 3개 이상인 멀티 클래스 분류문제에서 인공 신경망의 최종 LAYER 로 사용
로짓을 그대로 사용하지 않고, 지수함수를 취하는 이유는 값들 간의 차이를 더욱 두드러지게 하여 신경망 학습이 잘 되도록 하기 위함

'Deep Learning' 카테고리의 다른 글
| 최적화 개념과 gradient descent (0) | 2023.09.23 |
|---|---|
| 퍼셉트론 개념 (0) | 2023.09.22 |
| Embedding layer와 Embedding Vector의 Output 차이 정리 (0) | 2023.02.14 |
| Embedding Vector 과정 및 정의 (0) | 2022.11.19 |
| Dynamic programming (0) | 2022.05.15 |