
*Learning -> 환경의 모델을 모르지만 상호작용을 통해서 문제를 푸는 것

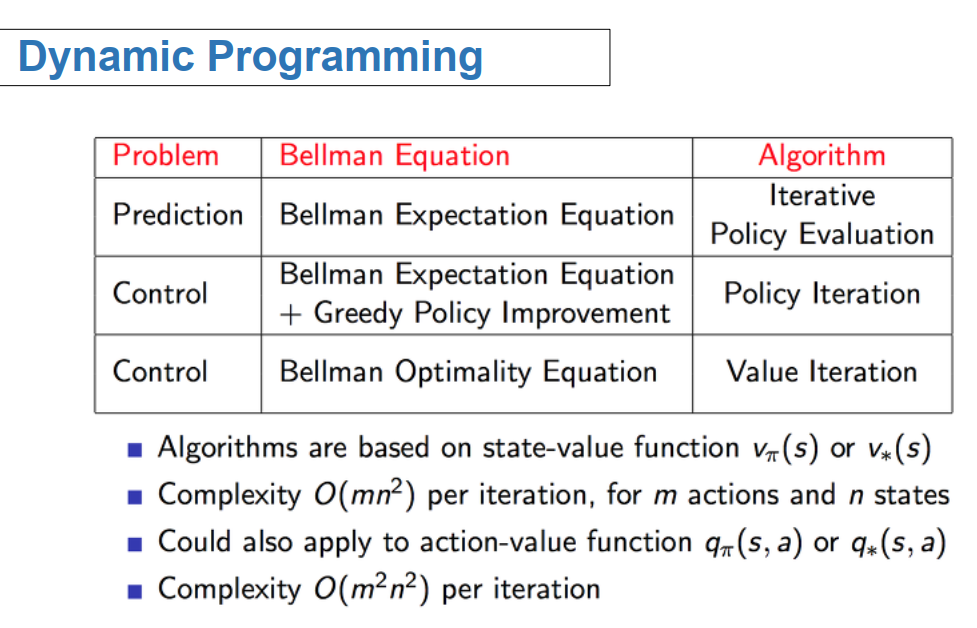
* value function이 작은 문제들의 해


1. optimal policy를 구하기위해서 policy를 랜덤하게 설정하고 이것이 수렴할 떄까지 반복할때
value function을 최대화 하는 것이 최적의 policy다 라는 의미



어느정도 수렴 (무한대) 가 되면 value function을 알 수 있음



value iteration은 앞의 두가지 과정을 한꺼번에 하는 것


반응형
'Deep Learning' 카테고리의 다른 글
| Embedding layer와 Embedding Vector의 Output 차이 정리 (0) | 2023.02.14 |
|---|---|
| Embedding Vector 과정 및 정의 (0) | 2022.11.19 |
| Markov Reward Process (0) | 2022.05.15 |
| 강화학습 (Reinforcement Learning) (0) | 2022.05.13 |
| Word2VeC (Cbow , Skip-gram) (0) | 2021.04.14 |