Word Embedding Vector


- Skip - gram : 주변 단어가 비슷한 단어일수록 비슷한 임베딩 값을 갖도록 학습
- Word2vec 하이퍼파라미터의 설정 값에 따라 각자 단어들 사이가 의미하는 벡터 값이 달라 질 여지가 많음
- 특수한 상황을 제외하고(product2vec 같은 것을 구현할 때 사용), 실제 NLP에서 드물게 활용됨
- 딥러닝은 END TO END를 지향하므로 중간 산출물을(embedding vector) 단독으로 쓰이는 것이 쉽지 않음
Embedding Layer
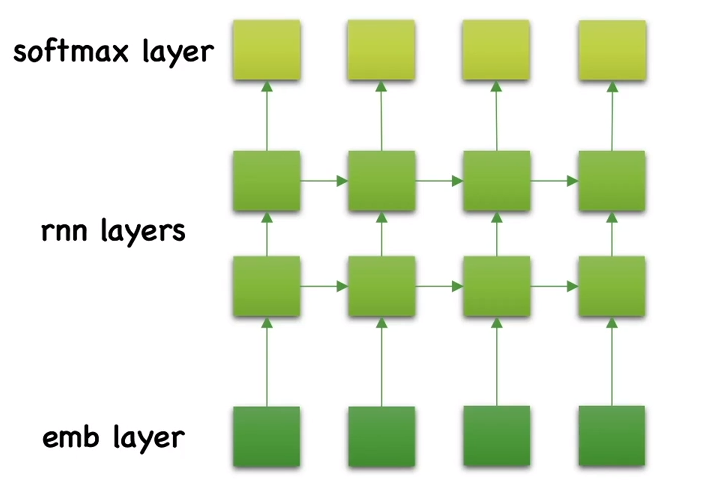

- 무작위로 특정 차원으로 입력 벡터들을 뿌린 후 학습을 통해 가중치들을 조정해 나가는 방식 즉, 단어 사이의 관계를 반영하는 방법이 아님
- 원핫 인코딩 된 이산 샘플의 벡터를 받아, 연속 벡터로 변환
- 높은 차원의 벡터를 효율적으로 계산하기 위함
- Loss를 최소화 하는 과정에서, 실제 자연스럽게 해당 Task에서 비슷한 쓰임새를 갖는 단어는 비슷한 벡터를 갖게 됨
- 사실상 Embedding layer를 사용하는 것이 Embedding vector를 가져다 쓰는 것보다 성능이 좋을 확률이 높음
- 추가 내용
skip -gram : corpus 전체에 대해서 해당 단어의 관계를 보는것
ELMO : Corpus 가 아닌 문장별로 단어의 관계를 보는 것 ( 이로인해 사과 : apple , apolozize 구분가능)
반응형
'Deep Learning' 카테고리의 다른 글
| 퍼셉트론 개념 (0) | 2023.09.22 |
|---|---|
| 손실함수 , 활성함수 정리 (0) | 2023.09.06 |
| Embedding Vector 과정 및 정의 (0) | 2022.11.19 |
| Dynamic programming (0) | 2022.05.15 |
| Markov Reward Process (0) | 2022.05.15 |