
1. K-means Clustering
-> 유사한 데이터 끼리 뭉치게 해서 그룹의 특성을 규명하는 것이 주목적이지 classification의 목적은 강하지 않음
-> k를 설정 초기 좌표는 Random


해당 데이터가 다른데이터로 할당 되지않을 때까지 계속 진행 -> 직관적인 장점
*거리 측정 기준
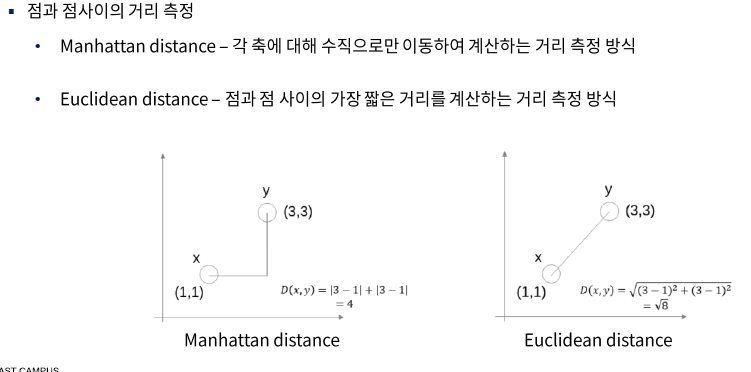
* 가장 좋은예시는 사전의 군집갯수(K)를 알고 시작하는것 ex) 기사 -정치,연예,스포츠
하지만 보통의 경우에는 사전 군집갯수를 알 수 없음

inertia -> 군집내 분산이 적어지는 시점이 최적의 K
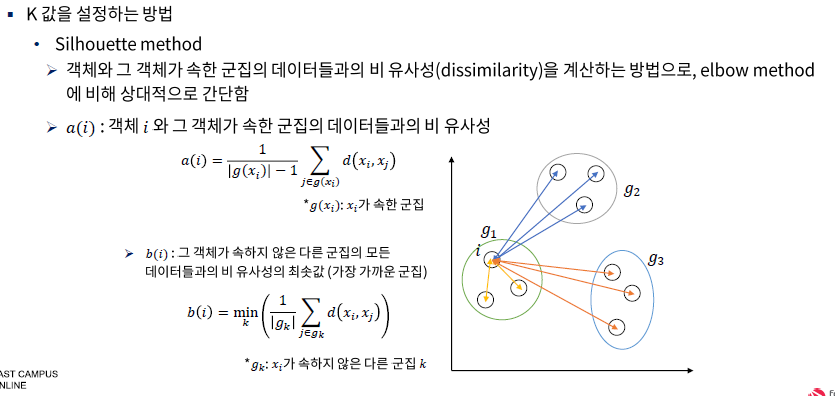
k-means clustering 단점
-> 데이터의 차원이 커질 수록 잘 맞지않음 . 2차원 3차원 까지는 알 수 있지만 4차원 부터는 거리에 대한 개념이
무감각해짐(컴퓨터도) 물론 구할 수는 있지만 실제로 가까운지에 대해서는 차원이 증가함에 따라 완전히 무의미해짐
그래서 거리를 기반으로하는 군집분석은 잘 맞지않을 확률이 커짐
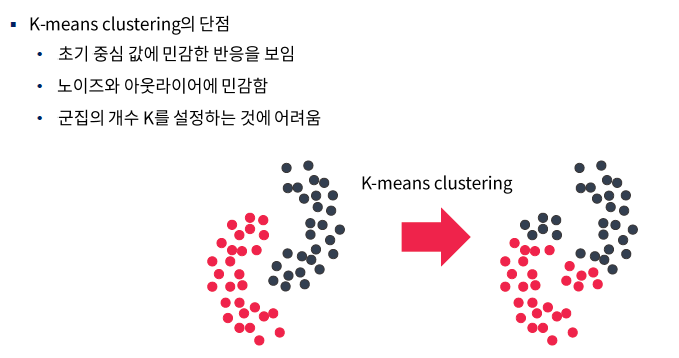

위 그림처럼 k-means 보다는 조금 좋은 모습을 보인다 특히 이상치에 있어서는 좀 더 강건한 모습을 보임

반응형
'Machine Learning' 카테고리의 다른 글
| Shap value - 중요 변수 추출 방법 (0) | 2020.06.30 |
|---|---|
| Hierachical , DBscan Clustering (0) | 2020.06.28 |
| KNN - K-nearest neighborhood (0) | 2020.06.27 |
| 나이브 베이즈 분류기 - Naive Bayesian classifier (0) | 2020.06.25 |
| SVM - Support Vector Machine (0) | 2020.06.23 |