* 데이터의 분포가정이 힘들 때, 아래의 데이터를 잘 나누려면 쓰는 것
-> Boundary에 집중하여 margin을 최대화 하는 Boundary를 찾는 것

기본 개념-> 선을 기준으로 점에 닿지 않으면서 기울기도 바꿔보고 평행이동도 해보면서 margin을 최대한 늘리는 것
Q1. 빨간 점과 초록점이 정확히 구분되지 않는 경우가 존재한다면?

A1. 적당한 error를 허용하고 ,이를 최소화하는 Boundary 결정
-> SVM은 기본적으로 범주형 변수일 때 쓰임
연속형은 SVR 개념에서 가능
기본적 IDEA-> 삐져나가는 점들에 대해 에러를 줘서 이러한 에러를 최소화하자는 방향으로 진행
회귀분석의 경우 선을 하나 긋고 그것에서의 에러를 다계산해서 모든에러를 반영해서 fitting을 하는거지만
SVM은 초평면을 기준으로 margin 바깥에 있는 점에 대해서만 penalty를 부여해서 안에 최대한 다 들어오게끔 해서 fitting 하는 것
모델 cost 는 cost에 영향을 끼칠점과 끼치지 않을 점을 구분을 하는데 그것을 margin에 포함되거나 되지않는 것으로 구분


1. Decision boundary
2. Lagrange multiplier(라그랑주 승수)
-> 어떤 목적함수를 최대화 하고 싶을 때 한정적인 조건이 있는 경우

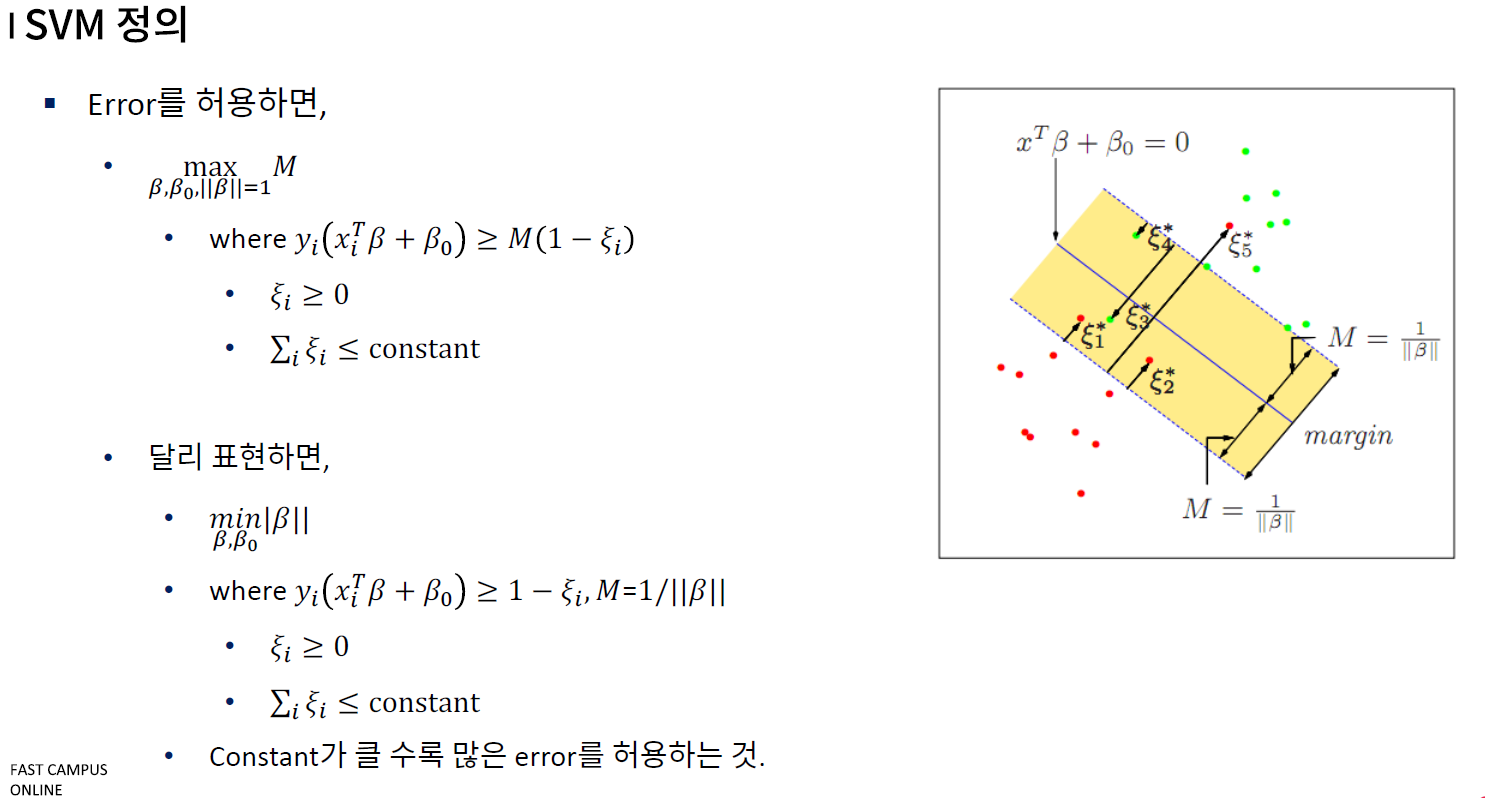




다른것 고려 없이 BOUNDARY 부근에서 MARGIN안에 있냐없냐 만을 보고 진행하므로 장점이 되고 정확도가 일반적으로 높다는 것이 강점
상대적으로 LDA 에 비해 단점은 C를 결정해야함(에러들의 합 앞에 붙은상수) C가커지면 에러가 최대한 안범하게 C가 무한대가 되면 에러가 하나도 없어야한다 C가작으면 에러가 좀있어도 된다라는 LOSS FUNCTION- COST FUNCTION안에 있던 상수
그러한 결정을 해야한다는 단점 그래서 파라미터를 결정하는데 시간이 걸림 , 모형구축자체 계산에 시간이 걸림
'Machine Learning' 카테고리의 다른 글
| KNN - K-nearest neighborhood (0) | 2020.06.27 |
|---|---|
| 나이브 베이즈 분류기 - Naive Bayesian classifier (0) | 2020.06.25 |
| Classification Tree , Regression Tree (0) | 2020.06.23 |
| 의사결정나무 - Decision Tree (0) | 2020.06.23 |
| 앙상블- Stacking , ensemble 의 ensemble (0) | 2020.06.18 |