
좀 더 크게 볼 수 있고 세세하게 볼 수 있는 것이 장점
1.Process
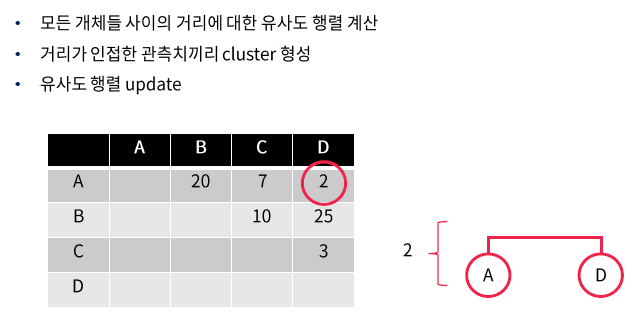
2.

3.

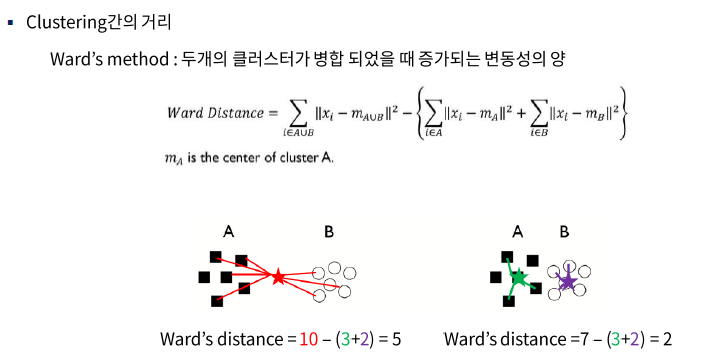
* 데이터와 데이터 간의 거리구하고 군집과 데이터 간의 유사도 구하고 업데이트하고 반복

2.DBSCAN Clustering
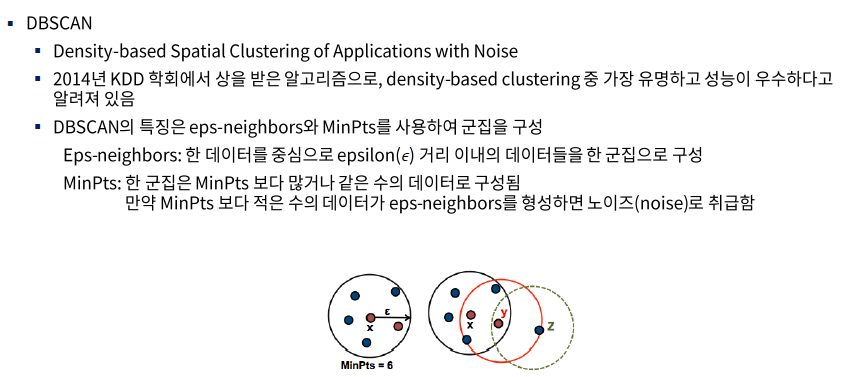

* 군집의 수를 설정할 필요없이 데이터의 밀도 기반으로 군집을 알아서 형성하고 군집에 속하지 않으면
Outlier 취급 해버린다.
한 데이터를 중심으로 엡실론(E, 최소거리) 거리 이내의 데이터들을 한 군집으로 구성하고 군집은 민 포인트보다 많거나 같은 수로
데이터가 구성됨. 만약 민 포인트보다 적은 수의 데이터가 군집을 형성하면 노이즈나 이상치로 취급함


반응형
'Machine Learning' 카테고리의 다른 글
| 모델의 정확도 지표(Accuracy,Recall,Precision,F1 Score) (0) | 2020.08.30 |
|---|---|
| Shap value - 중요 변수 추출 방법 (0) | 2020.06.30 |
| K-means , medoids Clustering (unsupervised learning) (0) | 2020.06.28 |
| KNN - K-nearest neighborhood (0) | 2020.06.27 |
| 나이브 베이즈 분류기 - Naive Bayesian classifier (0) | 2020.06.25 |