오늘은 R SDK를 사용해 자동차 사고로 인한 사망확률을 예측하는 로지스틱 회귀 + 모델 배포까지 학습하겠습니다.
* Azure 안에서 작업영역을 만드는 것은 생략
1. 개발환경 설정
library(azuremlsdk) # azure ml sdk 패키지를 불러옵니다
ws <- load_workspace_from_config() # config.json 파일에서 작업 영역 정보를 로드
experiment_name <- "accident-logreg"
exp <- experiment(ws, experiment_name) # 사고 데이터 모델을 학습하기 위해 caret 패키지 사용
cluster_name <- "rcluster"
compute_target <- get_compute(ws, cluster_name = cluster_name)
if (is.null(compute_target)) {
vm_size <- "STANDARD_D2_V2"
compute_target <- create_aml_compute(workspace = ws,
cluster_name = cluster_name,
vm_size = vm_size,
max_nodes = 1)
}
wait_for_provisioning_completion(compute_target)
# 작업 영역에 컴퓨팅 클러스터가 없으면 새로 생성, 없다면 프로비저닝 몇분 소요
2. 학습 위한 데이터 준비
nassCDS <- read.csv("nassCDS.csv",
colClasses=c("factor","numeric","factor",
"factor","factor","numeric",
"factor","numeric","numeric",
"numeric","character","character",
"numeric","numeric","character"))
accidents <- na.omit(nassCDS[,c("dead","dvcat","seatbelt","frontal","sex","ageOFocc","yearVeh","airbag","occRole")])
accidents$frontal <- factor(accidents$frontal, labels=c("notfrontal","frontal"))
accidents$occRole <- factor(accidents$occRole)
accidents$dvcat <- ordered(accidents$dvcat,
levels=c("1-9km/h","10-24","25-39","40-54","55+"))
saveRDS(accidents, file="accidents.Rd")
# 사망확률을 예측하는데 사용하는 변수와 여러 미국의 사고 데이터 포함
# 먼저 데이터 가져오고 분석위해서 데이터프레임 accidents로 변환하고 Rdata를 파일로 내보냄
ds <- get_default_datastore(ws)
target_path <- "accidentdata"
upload_files_to_datastore(ds,
list("./accidents.Rd"),
target_path = target_path,
overwrite = TRUE) # 원격 학습 환경에서 액세스할 수 있도록 클라우드에 사고 데이터 업로드
3. 모델 학습
est <- estimator(source_directory = ".",
entry_script = "accidents.R",
script_params = list("--data_folder" = ds$path(target_path)),
compute_target = compute_target
)

run <- submit_experiment(exp, est) # 클러스터에 실행할 작업 제출, 실행과 인터페이스 연결하는데 사용하는 Run개체 반환
wait_for_run_completion(run, show_output = TRUE)
# 모델 학습은 백그라운드에서 수행, 코드를 실행 전 모델 학습이 완료될 때까지 기다림
metrics <- get_run_metrics(run)
metrics # 학습 데이터의 예측 정확도에 해당하는 모델의 메트릭 로깅
download_files_from_run(run, prefix="outputs/")
accident_model <- readRDS("outputs/model.rds")
summary(accident_model)
# 학습된 모델을 다운
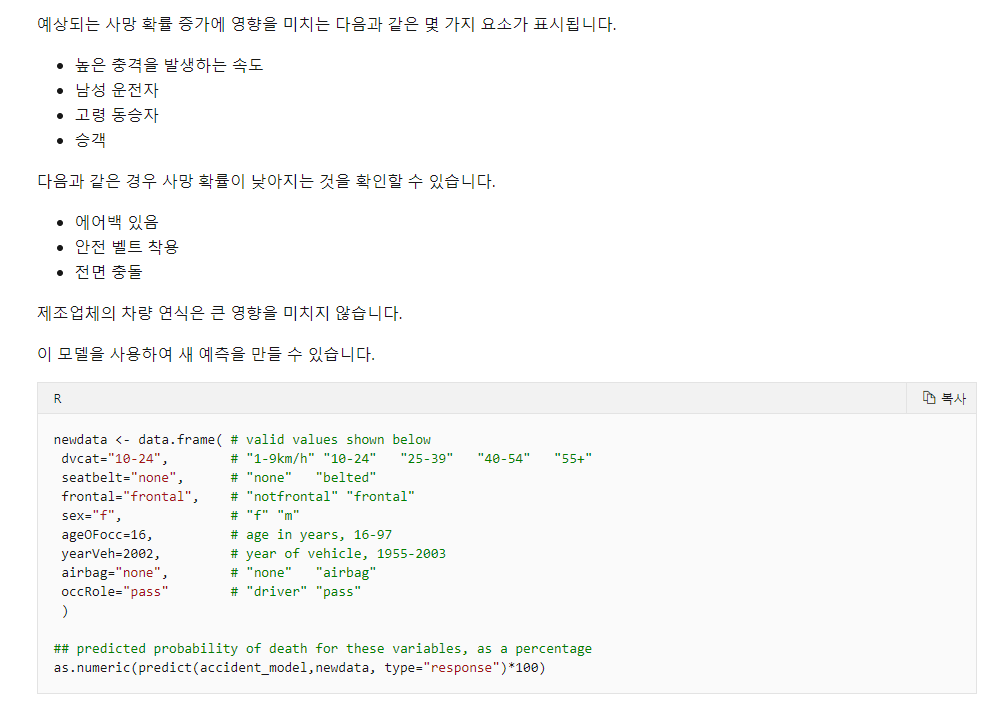
웹서비스로 배포
Azure ML을 사용하여 모델을 예측 서비스로 배포 -> AZURE container instances 에서 웹서비스를 배포
model <- register_model(ws,
model_path = "outputs/model.rds",
model_name = "accidents_model",
description = "Predict probablity of auto accident")
# 다운로드한 모델을 register_model() 을 사용하여 등록 , Azure ML은 배포를 위해 등록된 모델 사용
*추정값 종속성 정의
모델용 웹 서비스를 만드려면 먼저 입력 변수 값(json)으로 사용 후 모델에서 예측을 출력하는 스크립트인 Scoring (entry_script) 를 만들어야 함
여기서는 scoring file accident_predict.R 을 사용
socring file은 모델을 로드하고 해당 모델을 사용해서 입력 데이터를 기준으로 예측을 수행하는 함수를 반환하는 init() 메서드를 포함 해야함
r_env <- r_environment(name = "basic_env") #배포 위해 자체 Docker 이미지를 사용, custom_docker_image 매개 변수를 지정
inference_config <- inference_config(
entry_script = "accident_predict.R",
environment = r_env) # scoring file 스크립트 캡슐화하는 추정값 구성을 만드는 환경 구현
ACI 에 배포
aci_config <- aci_webservice_deployment_config(cpu_cores = 1, memory_gb = 0.5)
aci_service <- deploy_model(ws,
'accident-pred',
list(model),
inference_config,
aci_config)
wait_for_deployment(aci_service, show_output = TRUE)
# 단일 컨테이너를 프로비저닝 하고 테스트 및 인바운드 요청에 응답 + 웹 서비스 배포
'BigQuery' 카테고리의 다른 글
| AWS - RDBMS 생성 기초 (0) | 2021.04.19 |
|---|---|
| Azure Steaming Analytics (0) | 2020.08.25 |
| SQL 문법 + GCP 예제 (0) | 2020.08.08 |
| 파이썬을 통한 머신러닝 모델 배포 (0) | 2020.04.06 |