%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/Pokemon.csv")
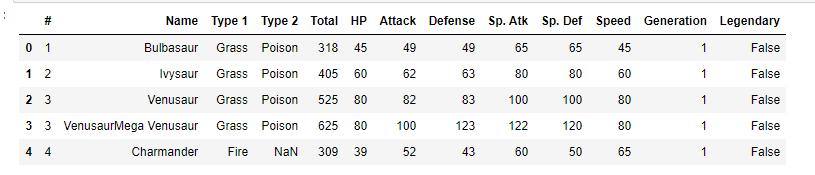
Feature Description
- Name : 포켓몬 이름
- Type 1 : 포켓몬 타입 1
- Type 2 : 포켓몬 타입 2
- Total : 포켓몬 총 능력치 (Sum of Attack, Sp. Atk, Defense, Sp. Def, Speed and HP)
- HP : 포켓몬 HP 능력치
- Attack : 포켓몬 Attack 능력치
- Defense : 포켓몬 Defense 능력치
- Sp. Atk : 포켓몬 Sp. Atk 능력치
- Sp. Def : 포켓몬 Sp. Def 능력치
- Speed : 포켓몬 Speed 능력치
- Generation : 포켓몬 세대
- Legendary : 전설의 포켓몬 여부
2) EDA (Exploratory Data Analysis : 탐색적 데이터 분석)
2-1) 기본 정보 탐색
데이터셋 기본 정보 탐색
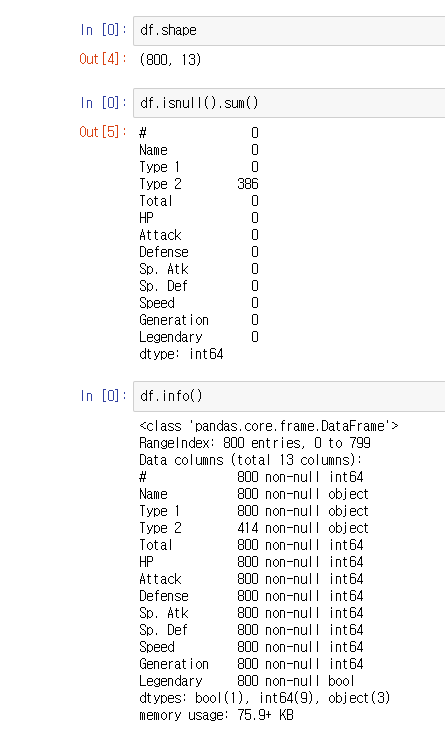
개별 피쳐 탐색

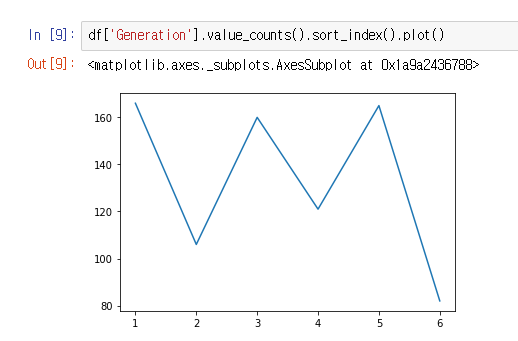
Genration별 갯수 시각화
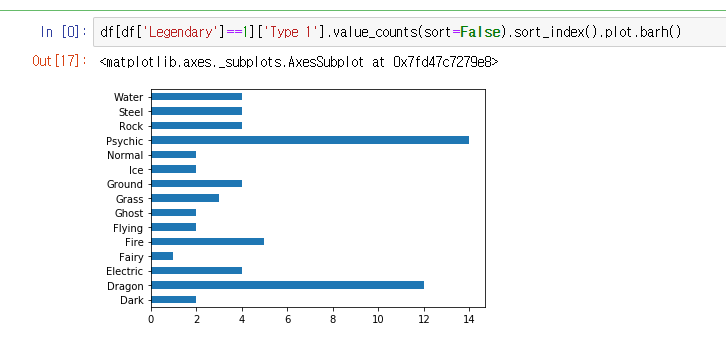
type 1에서 전설의 포켓몬 갯수 시각화
데이터 전처리
- 데이터 타입변경
df['Legendary'] = df['Legendary'].astype(int)
df['Generation'] = df['Generation'].astype(str)
preprocessed_df = df[['Type 1', 'Type 2', 'Total', 'HP', 'Attack',
'Defense', 'Sp. Atk', 'Sp. Def', 'Speed', 'Generation', 'Legendary']]
preprocessed_df.head() # generation은 string으로 legendary는 int로 타입변경
# one-hot encoding example
encoded_df = pd.get_dummies(preprocessed_df['Type 1'])
encoded_df.head() # type1을 더미데이터로 변경(원핫인코딩)
# pokemon type list 생성
def make_list(x1, x2):
type_list = []
type_list.append(x1)
if x2 is not np.nan:
type_list.append(x2)
return type_list
preprocessed_df['Type'] = preprocessed_df.apply(lambda x: make_list(x['Type 1'], x['Type 2']), axis=1)
preprocessed_df.head() # type1과 type2로 리스트를 만든다
del preprocessed_df['Type 1']
del preprocessed_df['Type 2']
preprocessed_df.head()#type1과 type2삭제
# multi label binarizer 적용
from sklearn.preprocessing import MultiLabelBinarizemlb = MultiLabelBinarizer()
preprocessed_df = preprocessed_df.join(pd.DataFrame(mlb.fit_transform(preprocessed_df.pop('Type')),
columns=mlb.classes_)) #
# apply one-hot encoding to 'Generation'
preprocessed_df = pd.get_dummies(preprocessed_df)
preprocessed_df.head()
from sklearn.preprocessing import StandardScaler
# feature standardization
scaler = StandardScaler()
scale_columns = ['Total', 'HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']
preprocessed_df[scale_columns] = scaler.fit_transform(preprocessed_df[scale_columns])
preprocessed_df.head()
from sklearn.model_selection import train_test_split
# dataset split to train/test
X = preprocessed_df.loc[:, preprocessed_df.columns != 'Legendary']
y = preprocessed_df['Legendary']
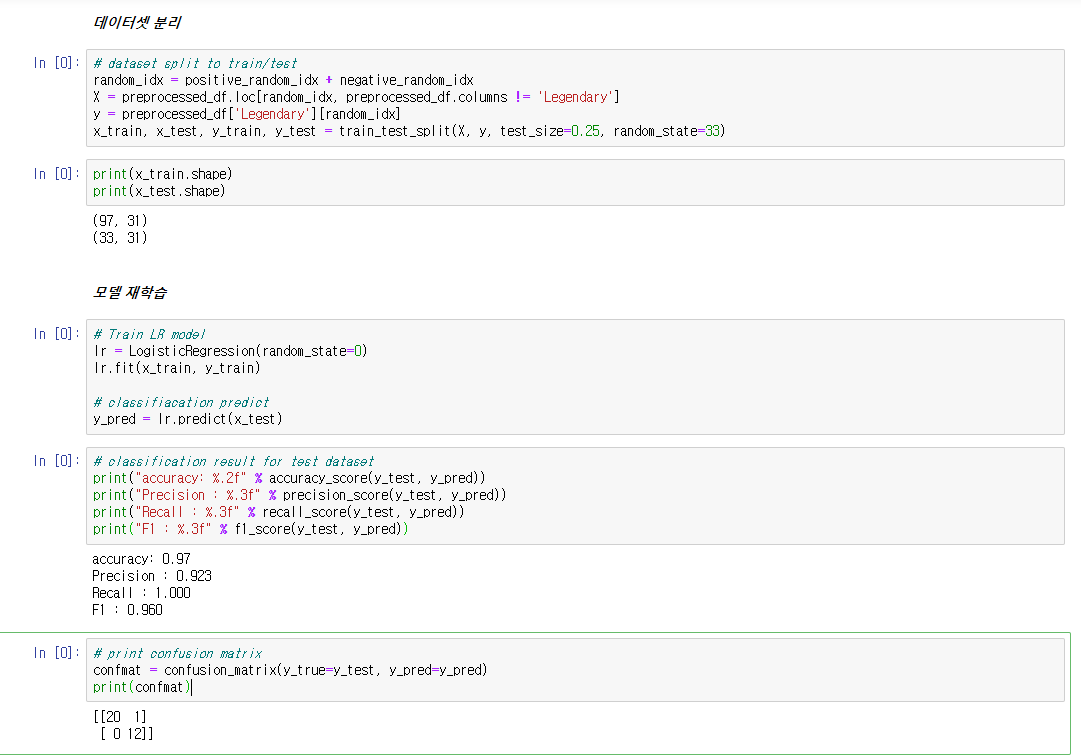
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)
3-2) Logistic Regression 모델 학습
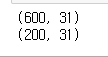
print(x_train.shape)
print(x_test.shape)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Train LR model
lr = LogisticRegression(random_state=0)
lr.fit(x_train, y_train)
# classifiacation predict
y_pred = lr.predict(x_test) # 모델학습
# classification result for test dataset
print("accuracy: %.2f" % accuracy_score(y_test, y_pred))
print("Precision : %.3f" % precision_score(y_test, y_pred))
print("Recall : %.3f" % recall_score(y_test, y_pred))
print("F1 : %.3f" % f1_score(y_test, y_pred)) #모델 평가
accuracy: 0.95 Precision : 0.615 Recall : 0.667 F1 : 0.640
from sklearn.metrics import confusion_matrix
# print confusion matrix
confmat = confusion_matrix(y_true=y_test, y_pred=y_pred)
print(confmat)

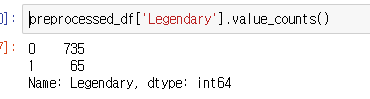
3-3) 클래스 불균형 조정¶
'Project & Kaggle' 카테고리의 다른 글
| Dog and cat Classification with CNN (0) | 2020.12.15 |
|---|---|
| 주택 가격 예측 with Deep Neural network (0) | 2020.12.11 |
| Deep learning( CNN을 활용한 Mnist classification kernel) (0) | 2020.11.30 |
| 사내 직원 이탈 모델링 (2) | 2020.09.04 |
| 보스턴 집 값 예측 - Boston Housing price Regression (0) | 2020.04.24 |