6.1 디자인 패턴 21 : 트랜스폼
입력,특징 변환을 신중하게 분리하여 ML 모델을 프로덕션으로 훨씬 쉽게 이동할 수 있게 하는 기법
6.1.1 문제
머신러닝 모델에 대한 입력은 머신러닝 모델이 계산에 사용하는 특징이 아니며 트랜스폼 디자인 패턴은 이 문제를 해결하고자 함
예를들어 텍스트 분류모델에서 입력은 원시 텍스트 문서이고 특징은 이 텍스트의 숫자 임베딩 표현
머신러닝 모델을 학습시킬때는 원시 입력에서 추출한 특징으로 학습
CREATE OR REPLACE MODEL `emart-dt-dev-ds.sample2.bicycle_model`
OPTIONS(input_label_cols=['duration'],
model_type='linear_reg')
AS
SELECT
duration
, start_station_name
, CAST(EXTRACT(dayofweek from start_date) AS STRING)
as dayofweek
, CAST(EXTRACT(hour from start_date) AS STRING)
as hourofday
FROM
`emart-dt-dev-ds.sample2.cycle_hire`이 모델에는 아래 그림에 표시된 것처럼 2개의 입력 (start_station_name,start_date)으로부터 계산된 세가지 특징 (start_station_name,dayofweek,hourofday) 존재

위의 SQL 코드는 입력과 특징이 섞여 있으며 입력에서 특징으로의 변환을 추적하지 않으므로, 이모델로 예측을 수행할 때는 문제가 발생 할 수 있으므로
예측은 다음과 같이 수행해야 함
SELECT * FROM ML.PREDICT(MODEL `emart-dt-dev-ds.sample2.bicycle_model`,(
'Kings Cross' AS start_station_name
,'3' as dayofweek
,'18' as hourofday
))
추론 시 모델이 학습한 특징 , 그 해석 방법 및 특징 변환의 세부사항을 알아야 하는데
예를들면 dayofweek의 '3'이 여기서 화요일인가 ? 수요일인가? 이런 부분들은 모델이 어떤라이브러리를 사용했고 일주일 시작을 언제로 지정했는지에 따라서 달라질 것
학습 환경과 서빙 환경 사이의 이러한 차이로 인해 발생하는 학습 제공 편향은 ML 모델을 프로덕션에 쓰기 어려운 주요한 이유 중 하나.
6.1.2 솔루션
이 문제의 솔루션은 모델 입력을 특징으로 변환하기 위해 적용된 변환을 명시적으로 포착하는 것.
빅쿼리 ML에서는 TRANSFORM 문법을 사용하여 수행할 수 있는데 TRANSFORM을 사용하면 ML.PREDICT 중에 이러한 변환이 자동으로 적용 된다
CREATE OR REPLACE MODEL `emart-dt-dev-ds.sample2.bicycle_model`
OPTIONS(input_label_cols=['duration'],
model_type='linear_reg')
TRANSFORM(SELECT*EXCEPT(start_date)
, CAST(EXTRACT(dayofweek from start_date) AS STRING)
as dayofweek --feature1
, CAST(EXTRACT(hour from start_date) AS STRING)
as hourofday --feature2
)
AS
SELECT
duration,start_station_name,start_date--inputs
FROM
`emart-dt-dev-ds.sample2.cycle_hire`입력(INPUT)과 특징(TRANSFORM)을 어떻게 구분했는지 확인 가능하고 이 상태에서는 예측하기가 훨씬 쉬움 start_station_name과 start_date만 모델에 보내면 된다.
SELECT * FROM ML.PREDICT(MODEL `emart-dt-dev-ds.sample2.bicycle_model`,(
'Kings Cross' AS start_station_name
,CURRENT_TIMESTAMP() as start_date
))이후에 모델에 필요한 feature를 만들기 위해 적절한 변환을 수행
변환 수행을 위해서는 갖고있는 변환 논리와 아티팩트(스케일링상수 임베딩 계수 조회 테이블) 모두를 사용
SELECT 문에서 원시 입력만 신중하게 사용하고 이후의 모든 입력 처리를 TRANSFORM 절에 넣으면, 빅쿼리 ML은 예측 중에 이러한 변환을 자동으로 적용
6.1.3 트레이드 오프와 대안
솔루션에서 설명한 방식은 빅쿼리 ML이 변환 논리 및 아티팩트를 추적 및 모델 그래프에 저장하고 예측중에 변환을 자동으로 적용하기 때문에 작동이 가능하다
트랜스폼 디자인 패턴에 대한 지원이 내장되지 않은 프레임워크를 사용하는 경우 학습 중에수행된 변환이 서빙중에 쉽게 재현될 수 있도록 모델 아키텍쳐를 설계해야함
이를 위해 모델 그래프에 변환을 저장하거나 변환된 특징 저장소를 생성하는 방식을 사용할 수 있다.
텐서플로와 케라스에서의 변환
뉴욕의 택시요금 추정을 위한 ML 모델에 6개의 입력 (픽업 위도 , 픽업 경도, 하차 위도 , 하차 경도, 승객 수, 픽업시간) 이 있다고 가정해보자.
텐서플로는 모델그래프에 저장되는 '특정 열' 이라는 개념을 지원한다.
그러나 API는 원시 입력이 특징과 동일하다는 가정하에 설계되어있는 상황이라면
위도와 경도를 스케일링하고 이를 유클리드 거리라는 특징으로 변환하고 타임스탬프에서 시간을 추출한다고 가정한다면
트랜스폼 디자인패턴의 개념을 숙지하고 모델 그래프를 신중하게 설계해야 함 (아래 그림 참조)
아래 코드를 살펴보면서 케라스 모델에서 입력 계층 , 변환 계층, dense features 게층의 세가지 개별계층을 명확하게 설계하도록 설정하는 방법을 확인해보자.
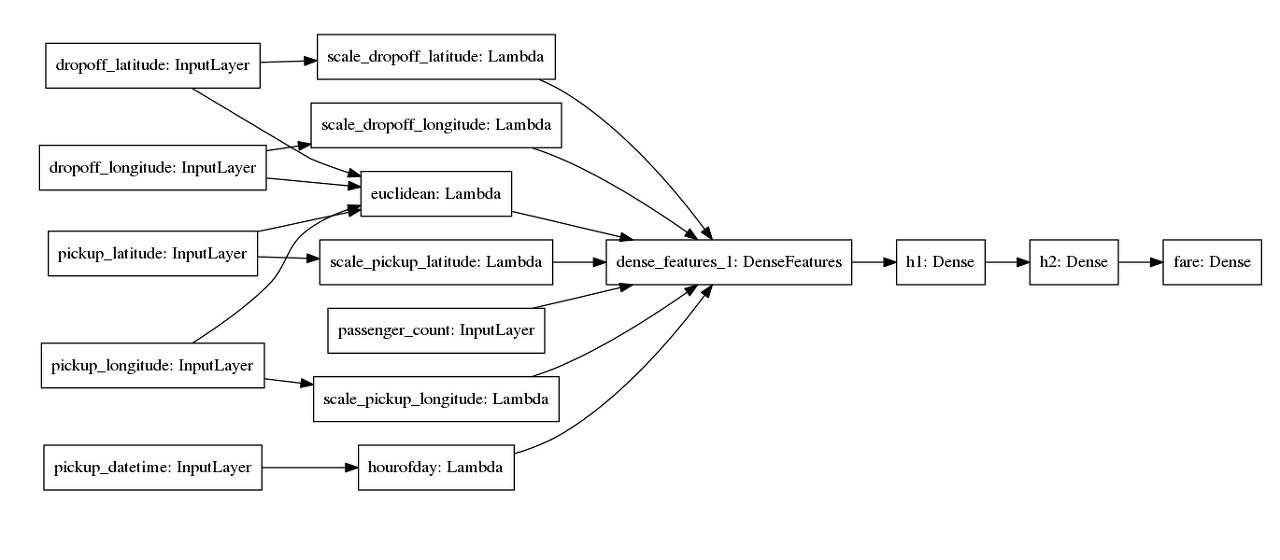
<그림 6-2>
먼저 케라스 모델에 대한 모든 입력을 입력 계층으로 만든다.
%%bigquery preds
inputs = {
colname : tf.keras.layers.Input(
name-colname,shape=(), dtype='float32')
for colname in ['pickup_longitude' , 'pickup_latitude',
'dropoff_longitude','dropoff_latitude']
}[그림 6-2]에서 이는 dropoff_laitude(하차 위도), dropoff_logitude(하차 경도) 등으로 표시된 상자
다음으로 변환된 특징의 사전을 유지하면서 모든 변환을 케라스 전처리 계층 또는 Lambda 계층으로 만든다. 여기에서는 lambda 계층을 사용하여 입력을 스케일링
for lon_col in ['pickup_longitude', 'dropoff_longitude']: # in range -70 to -78
transformed[lon_col] = tf.keras.layers.Lambda(
lambda x: (x+78)/8.0,
name='scale_{}'.format(lon_col)
)(inputs[lon_col])
for lat_col in ['pickup_latitude', 'dropoff_latitude']: # in range 37 to 45
transformed[lat_col] = tf.keras.layers.Lambda(
lambda x: (x-37)/8.0,
name='scale_{}'.format(lat_col)
)(inputs[lat_col])그림 6-2 에서 이는 scale_dropoff_latitude,scale_dropoff_longitude등으로 표시된 상자
또한 4개의 입력 계층에서 계산되는 유클리드 거리에 대해 하나의 lambda 계층을 갖게 된다.
def euclidean(params):
lon1, lat1, lon2, lat2 = params
londiff = lon2 - lon1
latdiff = lat2 - lat1
return tf.sqrt(londiff*londiff + latdiff*latdiff)
transformed['euclidean'] = tf.keras.layers.Lambda(euclidean, name='euclidean')([
inputs['pickup_longitude'],
inputs['pickup_latitude'],
inputs['dropoff_longitude'],
inputs['dropoff_latitude']
])마찬가지로 타임스탬프에서 시간을 생성하는 열도 lambda 계층
transformed['hourofday'] = tf.keras.layers.Lambda(
lambda x: tf.strings.to_number(tf.strings.substr(x, 11, 2), out_type=tf.dtypes.int32),
name='hourofday'
)(inputs['pickup_datetime'])이렇게 변형된 모든 계층은 DenseFeatures 계층으로 연결된다.
dnn_inputs = tf.keras.layers.DenseFeatures(feature_columns.values())(transformed)DenseFeature 의 생성자에는 특정 열 집합이 필요하기 때문에, 변환된 각 값을 가져와 신경망에 대한 입력으로 변환하는 방법을 지정해야한다
그대로 사용하거나, 원핫인코딩하거나 숫자를 버킷하거나, 일단은 단순성을 위해 있는 그대로 사용
feature_columns = {
colname: tf.feature_column.numeric_column(colname)
for colname in NUMERIC_COLS
feature_columns['euclidean'] = tf.feature_column.numeric_column('euclidean')DenseFeatrues 입력 계층이 있으면 평소와 마찬가지로 나머지 케라스 모델을 빌드할 수 있다
h1 = tf.keras.layers.Dense(32, activation='relu', name='h1')(dnn_inputs)
h2 = tf.keras.layers.Dense(8, activation='relu', name='h2')(h1)
output = tf.keras.layers.Dense(1, name='fare')(h2)
model = tf.keras.models.Model(inputs, output)
model.compile(optimizer='adam', loss='mse', metrics=[rmse, 'mse'])케라스 모델의 첫번째 계층이 입력이 되도록 설정 하는 방법에 주목해보면 두번째 계층은 Transform 계층 세번째 계층은 이들을 결합한 DenseFeatrues 계층
이러한 3개 계층 이후에 일반적인 모델 아키텍처가 시작되고 Transform 계층은 모델 그래프의 일부이기 때문에<ㅠㄱ> 일반적인 서빙 함수 및 배치 서빙 솔루션 도 그대로 작동한다.
'머신러닝 디자인패턴' 카테고리의 다른 글
| 멀티 모달 입력 (0) | 2023.03.04 |
|---|---|
| 디자인패턴 29 : 설명 가능한 예측 (0) | 2022.06.01 |
| 디자인패턴 17 : 배치서빙 (0) | 2022.06.01 |
| 디자인 패턴 15 : 하이퍼 파라미터 튜닝 (0) | 2022.06.01 |
| 디자인 패턴 9 : 중립 클래스 (0) | 2022.06.01 |